Optymalizacja kosztów LLM, czyli jak płacić mniej za AI.

Czy LLM są drogie? To zależy. Dla osoby, która korzysta z nich osobiście, pewnie nie. Ale gdy wrzucimy to do aplikacji z tysiącem użytkowników, to nie jest już tak kolorowo. Warto wiedzieć, jak podejść do kwestii optymalizacji i jakie techniki można zastosować.
Dlaczego LLM są tak drogie?
Głównym problemem sztucznej inteligencji jest cennik i sposób rozliczania za wykorzystywanie. Aktualnie większość cenników przeszła na rozliczanie per milion tokenów. I zazwyczaj te ceny nie są straszne (zazwyczaj w okolicach 2-20$ dla większości). Problemem jest to, że ciężko oszacować liczbę zużywanych tokenów w aplikacji, gdy:
- dorzucamy dane dynamiczne,
- mamy architekturę agentową, więc nie wiemy, ile razy wywołujemy LLM,
- mamy dużą ilość użytkowników.
I nagle koszt 5-10$ przy korzystaniu prywatnym, co jest w porządku, może być zabójczy w aplikacji z 1 tys. użytkowników. LLM są zawsze tanie w małej skali, ale w dużej koszty potrafią być zabójcze. Dlatego tak ważne jest, by podczas PoC wyliczać koszty na bazie aktualnej liczby użytkowników.
Redukcja kosztów nie może powodować zmniejszenia jakości odpowiedzi.
Strategie optymalizacji kosztów AI
Oczywiście nie ma złotego sposobu, by zoptymalizować koszty AI dla każdej aplikacji. Wszystko zależy od typu aplikacji i tego, jak AI zostało użyte. Ale jest kilka sposobów, które warto wypróbować, bo każdy zaoszczędzony cent dla użytkownika rośnie w kontekście całej aplikacji.
Przerzucenie kosztu na użytkownika
Najczęściej spotykanym sposobem na oszczędność jest przerzucanie kosztu AI na użytkownika. Bardzo dobrze to widać w różnych aplikacjach, gdzie w podstawowym planie jest pewna liczba kredytów na operacje AI, a potem trzeba czekać na następny miesiąc lub dokupić kredyty. Jest to szybki sposób na zapewnienie płynności rozwiązania i ograniczenie wykorzystywania AI przez klientów. Ale nie sprawdzi się przy AI stosowanych w procesach wewnętrznych.
Redukcja liczby tokenów
Najskuteczniejszym, ale i najtrudniejszym sposobem jest redukcja liczby tokenów, jakie wysyłamy i otrzymujemy. Tu najważniejsze jest napisanie odpowiedniego prompta, który będzie sterował zachowaniem LLM. Jeśli chodzi o output tokens, to warto zwrócić uwagę na:
- dokładne opisanie wyniku (np.: podaj tylko wynik bez dodatkowego opisu),
- wykorzystanie funkcjonalności w stylu Structured Outputs, gdy zależy nam na konkretnym kształcie.
W optymalizacji input tokens może pomóc:
- Optymalizacja samego promptu. Tutaj po pierwsze warto testować różne prompty i sprawdzić, który ma największą skuteczność przy najmniejszej liczbie tokenów. Język angielski jest pod tym względem najlepszy.
- Wykorzystanie narzędzi do automatycznej optymalizacji promptów, które przebudują prompt i zoptymalizują pod konkretny cel. Warto najpierw napisać zestaw testów pod ten przypadek, by móc kontrolować zmiany.
- Optymalizacja kontekstu. To, że modele mają coraz większy kontekst, nie znaczy, że trzeba go w całości wypełniać. Do zapytania trzeba wrzucić tyle danych, ile tylko potrzebujemy. Im mniej danych wrzucimy, tym lepiej. Lepiej mniej danych, ale bardziej dokładnych.
- Ograniczenia dla użytkowników. Jeśli mamy rozwiązanie AI typu chat, to warto wdrożyć ograniczenia długości wiadomości wysyłanej przez użytkownika. Po co nasze optymalizacje prompta, kiedy użytkownik wrzuci całego Pana Tadeusza?
Zarządzanie modelami LLM w środowisku produkcyjnym
Czy kazałbyś doktorowi matematyki rozwiązywać zadanie z 5. klasy podstawówki? To dlaczego używasz najmocniejszych modeli do najprostszych zadań? Mamy aktualnie wysyp różnych modeli o różnym poziomie zaawansowania. I wiadomo - korci, by używać tych najmocniejszych. Ale to nie jest dobry sposób, jeśli zależy nam na optymalizacji kosztowej.
W każdej aplikacji korzystającej z LLM są różne zadania i każde wymaga innego poziomu szybkości działania i „inteligencji”. Budując takie rozwiązanie, trzeba patrzeć na to, co wymagamy od modelu (reasoning, multimodal, tool calls etc.) i dobrać najtańszy model, który realizuje zadanie.
Oczywiście nie można też przegiąć w drugą stronę i korzystać z słabych modeli, które nie realizują zadania. Trzeba dobrać odpowiedni model do zadania i monitorować aplikację.
Trzeba też pamiętać o monitorowaniu cen i nowych modeli, ponieważ ceny się zmieniają, stare modele tanieją, a czasem nowe są tańsze w porównaniu do możliwości, jakie dają. Kurczowe trzymanie się aktualnych modeli może być szkodliwe.
Nie zawsze potrzebujesz LLM
Duże modele językowe są najbardziej popularnym i rozreklamowanym rozwiązaniem. Ale istnieje wiele mniejszych i bardziej wyspecjalizowanych modeli. Główną zaletą tych mniejszych modeli jest ich wielkość, przez co rozwiązania oparte na nich mogą być uruchamiane na słabszym sprzęcie, a czasem wystarczy samo CPU. Dzięki temu mamy AI, ale nie musimy płacić za dodatkowy sprzęt czy optymalizować każdy token. Warto sprawdzić Huggingface i modele, które są tam dostępne.
Optymalizacja liczby zapytań
Wizja architektury agentowej, gdzie wszystko dzieje się automatycznie, jest kusząca. Ale czy zdajesz sobie sprawę, że każda operacja agenta kosztuje? Więc może zamiast kazać agentowi robić kilka zapytań (pobierz dane użytkownika, wykonaj akcję, pobierz szczegóły akcji, dociągnij dane z dodatkowego endpointa), zoptymalizować wszystko pod jedną akcją? Pod spodem to dalej może być kilka wywołań, ale AI nie musi tego wiedzieć.
Optymalizacja procesu
Czy używasz młotka do wkręcania śruby? To dlaczego próbujesz wsadzić AI do każdego elementu procesu albo wręcz zastąpić proces za pomocą AI? Tradycyjne programowanie jest dalej przydatne i konieczne. Może zamiast tworzyć skomplikowaną architekturę agentową wystarczy ci jeden model, który przeanalizuje zapytanie użytkownika, wybierze narzędzie i zwróci wynik. AI musi być precyzyjnie zaaplikowane, by przynosić zysk. Nie wszystko musi być robione przez AI. Czasem może być taniej połączyć AI i człowieka, zamiast tworzyć zaawansowane procesy AI do obsługi wszystkiego.
Self-hosted model
Przy bardzo dużej skali cennik za ilość tokenów źle się skaluje. Wtedy rozwiązaniem może być samodzielne hostowanie modeli lub skorzystanie z chmury i płatności za godzinę pracy modelu. Oczywiście to nie jest tania opcja. By hostować lokalnie, potrzebujesz maszyn z GPU i dużą ilością pamięci. Nie będziesz też w stanie hostować najbardziej popularnych modeli językowych, bo nie są dostępne w modelu open-source. To można zrobić u dostawców chmurowych, rezerwując zasoby obliczeniowe na jakiś czas.
Prompt caching
Jest to ciekawa technika, która pozwala oszczędzić pieniądze w przypadku powtarzających się zapytań. Przydaje się, gdy mamy powtarzającą się treść w kolejnych zapytaniach, np.: analizujemy duży dokument. Dzięki temu, że damy ten dokument do cache, będziemy płacić mniej za kolejne zapytania. Oczywiście nie sprawdzi się to w mocno dynamicznych aplikacjach. U każdego dostawcy działa to trochę inaczej i warto poczytać o tym, jak to wdrożyć u siebie w aplikacji (np.: w OpenAI działa automatycznie, a w modelach Anthropic możemy sami tym sterować). Dodatkowo optymalizujemy szybkość generowania odpowiedzi.
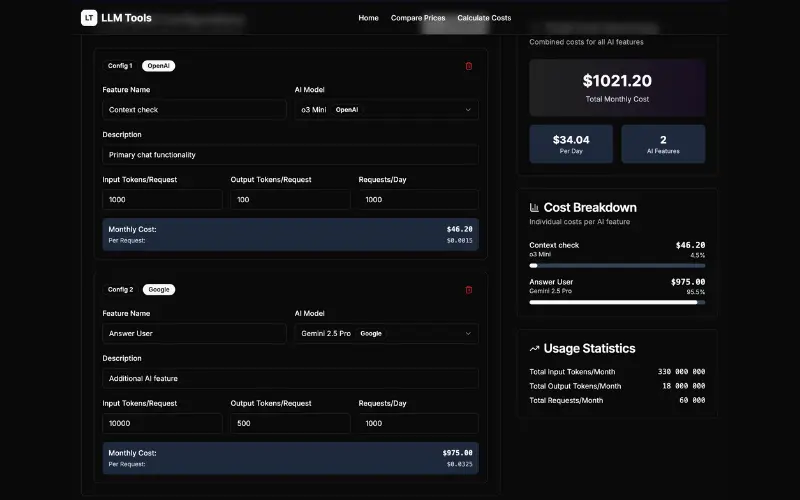
Jak sprawdzić, czy faktycznie rozwiązanie AI jest opłacalne?
Zanim wdrożysz aplikację albo funkcjonalność korzystającą z AI, należy wszystko przeliczyć. Punktem wyjścia jest poprawnie zbudowany PoC, który potwierdził wykonalność pomysłu oraz zdefiniował, co jest potrzebne do wdrożenia. Następnie trzeba wziąć Excela i policzyć całkowite koszty oraz porównać z istniejącym procesem, np.:
- budując chat, musimy policzyć, ilu użytkowników będzie korzystać, ile wiadomości miesięcznie oraz ile mniej więcej tokenów zużyją przy jednej wiadomości i porównać np. z kosztem obsługi klienta,
- budując rozwiązanie do analizy dokumentów, trzeba sprawdzić, ile dokumentów miesięcznie przetwarzamy, jaka jest ich wielkość, czas potrzebny na przetworzenie i porównać z czasem człowieka.
Liczenie tego wszystkiego może być skomplikowane i łatwo się pomylić, jeśli korzystamy z różnych modeli językowych. Dlatego stworzyłem proste narzędzie, które pomoże ci oszacować koszty twojej aplikacji AI. Wszystko działa lokalnie w przeglądarce i nic nie jest wysyłane na serwer. Możesz spokojnie policzyć wszystko i wyeksportować raport. A jak wyjdzie nowy model, to możesz oszacować koszty z nowymi modelami. Kalkulator znajdziesz na stronie LLM Tools.